PoplarML: Effortless ML Model Deployment and Scalability
Revolutionize your ML deployment process with PoplarML's one-click deployment and support for various frameworks. Realize real-time inference with minimal engineering effort.
Features
- One Click Deploys: Effortlessly deploy machine learning models to a fleet of GPUs with our intuitive CLI tool, streamlining your workflow.
- Real-time Inference: Invoke deployed models through a REST API for instant, real-time inference, providing responsive ML solutions.
- Framework Agnostic: Flexible model deployment for Tensorflow, Pytorch, or JAX, enabling you to bring your preferred tools to the production environment.
Use Cases:
- Production-Ready Deployment: Transition from training to production seamlessly, with scalable infrastructure ready for your ML models.
- Rapid Prototyping to Scalability: From initial prototype to full-scale deployment, PoplarML is designed to grow with your application's needs.
PoplarML is your go-to platform for deploying and scaling machine learning models with speed and flexibility, accommodating various frameworks and enabling real-time inference.


PoplarML Alternatives:

1. Cerebrium
Cerebrium enables easy training, deployment, and monitoring of serverless machine learning models.

2. MLnative
Streamlines machine learning model deployment, management, and inference with secure efficiency.

3. StackML
Browser-based machine learning integration for easy app development with real-time analytics.

4. MarkovML
AI-powered no-code platform for easy data insights and collaborative analytics.


6. Sagify
Command-line tool simplifying ML model training and deployment on AWS SageMaker.
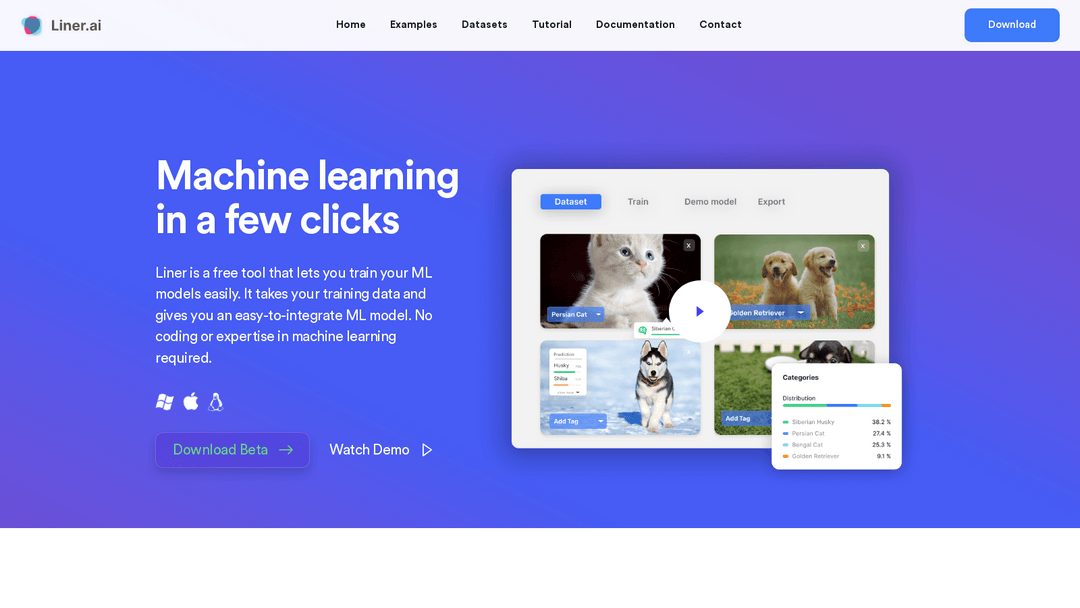
7. Liner.ai
Streamlines machine learning model training and deployment; no coding needed, free.

8. Pipeline AI
Fast, scalable, and portable solution for deploying pipelines. Join the waitlist!